Google Summer of Code 2016 Blogpost 5 - Code Quality in the knittingpattern Python Library
Code Quality in the knittingpattern Python Library
In our Google Summer of Code project a part of our work is to bring knitting to the digital age. We is Kirstin Heidler and Nicco Kunzmann. Our knittingpattern library aims at being the exchange and conversion format between different types of knit work representations: hand knitting instructions, machine commands for different machines and SVG schemata.
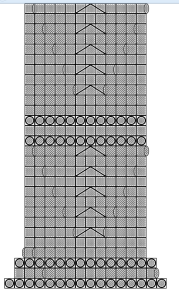 The generated schema from the knittingpattern library.
The generated schema from the knittingpattern library.
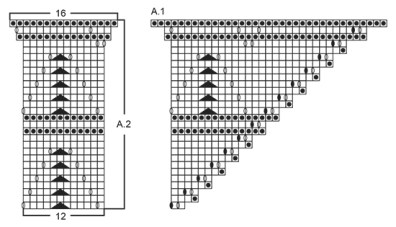 The original pattern schema Cafe.
The original pattern schema Cafe.
The image above was generated by this Python code:
import knittingpattern, webbrowser
example = knittingpattern.load_from().example("Cafe.json")
webbrowser.open(example.to_svg(25).temporary_path(".svg"))
So far about the context. Now about the Quality tools we use:

Continuous integration
We use Travis CI [FOSSASIA] to upload packages of a specific git tag automatically. The Travis build runs under Python 3.3 to 3.5. It first builds the package and then installs it with its dependencies. To upload tags automatically, one can configure Travis, preferably with the command line interface, to save username and password for the Python Package Index (Pypi).(TravisDocs) Our process of releasing a new version is the following:
- Increase the version in the knitting pattern library and create a new pull request for it.
- Merge the pull request after the tests passed.
- Pull and create a new release with a git tag using
setup.py tag_and_deploy
Travis then builds the new tag and uploads it to Pypi.
With this we have a basic quality assurance. Pull-requests need to run all tests before they can be merge. Travis can be configured to automatically reject a request with errors.
Documentation Driven Development
As mentioned in a blog post, documentation-driven development was something worth to check out. In our case that means writing the documentation first, then the tests and then the code.
Writing the documentation first means thinking in the space of the mental model you have for the code. It defines the interfaces you would be happy to use. A lot of edge cases can be thought of at this point.
When writing the tests, they are often split up and do not represent the flow of thought any more that you had when thinking about your wishes. Tests can be seen as the glue between the code and the documentation. As it is with writing code to pass the tests, in the conversation between the tests and the documentation I find out some things I have forgotten.
When writing the code in a test-driven way, another conversation starts. I call implementing the tests conversation because the tests talk to the code that it should be different and the code tells the tests their inconsistencies like misspellings and bloated interfaces.
With writing documentation first, we have the chance to have two conversations about our code, in spoken language and in code. I like it when the code hears my wishes, so I prefer to talk a bit more.
Testing the Documentation
Our documentation is hosted on Read the Docs. It should have these properties:
- Every module is documented.
- Everything that is public is documented.
- The documentation is syntactically correct.
These are qualities that can be tested, so they are tested. The code can not be deployed if it does not meet these standards. We use Sphinx for building the docs. That makes it possible to tests these properties in this way:
- For every module there exists a .rst file which automatically documents the module with autodoc.
- A Sphinx build outputs a list of objects that should be covered by documentation but are not.
- Sphinx outputs warnings throughout the build.
testing out documentation allows us to have it in higher quality. Many more tests could be imagined, but the basic ones already help.
Code Coverage)
It is possible to test your code coverage and see how well we do using Codeclimate.com. It gives us the files we need to work on when we want to improve the quality of the package.
Landscape
Landscape is also free for open source projects. It can give hints about where to improve next. Also it is possible to fail pull requests if the quality decreases. It shows code duplication and can run pylint. Currently, most of the style problems arise from undocumented tests.
Summary
When starting with the more strict quality assurance, the question arose if that would only slow us down. Now, we have learned to write properly styled pep8 code and begin to automatically do what pylint demands. High test-coverage allows us to change the underlying functionality without changing the interface and without fear we may break something irrecoverably. I feel like having a burden taken from me with all those free tools for open-source software that spare my time to set quality assurance up.
Future Work
In the future we like to also create a user interface. It is hard, sometimes, to test these. So, we plan not to put it into the package but build it on the package.
— Nicco Kunzmann